
SDS
redis中没有直接使用C语言的字符串,而是自定义了一种名为简单动态字符串的抽象类型——SDS。我们下载redis源码,可以在src目录下找到一个sds.h的文件,打开这个文件查看它的部分代码:
1 |
|
根据代码注释我们知道:
- len 表示字符串长度
- alloc 表示实际分配的空间
- flags 低三位表示类型,高五位未使用
- buf 存储的字符
因此sds示意图就是这样的: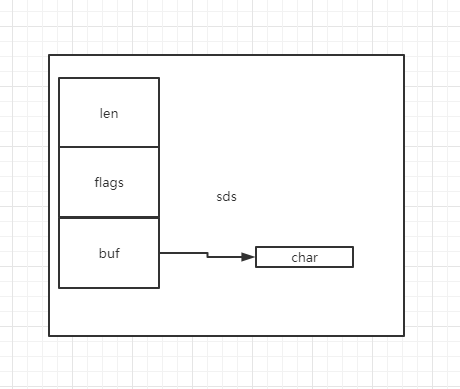
那么redis为什么要这么设计呢,出于以下几点考虑:
- 降低获取字符串长度的复杂度,通过获取sds的len属性就能直接获取字符串长度。
- 避免缓冲区溢出,当拼接字符串的时候可以通过alloc属性判断是否会超出长度
- 减少修改字符串所带来的内存重新分配次数。因为sds会预留内存空间(alloc>len),如果修改后的字符串长度小于alloc,则不需要重新分配内存
链表
在redis 源码中链表的定义可以通过adlist.h查看:
1 | /* Node, List, and Iterator are the only data structures used currently. */ |
从源码我们可以看出链表由三个结构体来维护,list \ listNode \ listIter 。list结构为链表提供了表头指针 head,表尾指针 tail,链表长度 len。redis 链表有以下特点:
- 双端:listNode 带有prev和next属性,它们分别指向前置节点和后置节点,从而构成双端队列;
- 有表头表尾指针:表头指针head,表尾指针tail,降低程序获得表头指针表尾指针的复杂度;
- 有链表长度:list中属性len记录了链表长度,使其降低了获得链表长度的复杂度。
字典
字典即map,redis字典使用哈希表作为底层的实现,每个哈希表节点中保存字典中的一个键值对。在redis的源码中可以通过dict.h 查看字典的定义:
1 | typedef struct dictEntry { |
我们看到源码中有dictType,dictEntry,dict,dictIterator,dictht这几个结构体来维护字典结构,(7.0以后版本无dictht)。
其中dictIterator为字典的迭代器,dictEntry结构保存着一个键值对,dictEntry属性说明:
- key保存键值对中的键;
- v 保存键值对中的值;
- next指向另一个哈希节点的指针。
结构体dictType 定义了一堆用于处理键值的函数,我们可以不去关心。
dictht是一个哈希表结构,它通过将哈希值相同的元素放到一个链表中来解决冲突问题,属性说明:
- table: dictEntry节点指针数组;
- size: 桶的数量;
- sizemask: mask 码,用于地址索引计算;
- used: 已有节点数量
结构体dict 包含的属性有:
- type:是一个指向
dictType结构的指针; - privdata: 传给类型特定函数的可选参数;
- ht[2]: 长度为2的
dictht哈希表; - rehashidx:指示 rehash 是否正在进行,如果不是则为 -1;
- iterators:当前正在使用的 iterator 的数量。
redis的hash算法使用的是MurmurHash2,具体算法细节不做介绍。随着对hash的操作其中的键值对会发生改变,这个时候为了更合理的分配空间就需要进行hash重算(rehash)。
在dict中ht属性是一个长度为2的dictht数组,当进行hash重算的时候会将ht[0]的键值对rehash到ht[1]里面。rehash这个过程不是一次性完成的,是多次渐进式地去完成的。
rehash过程:
- 将rehashidx置0,表示rehash工作开始.
- 当对字典进行增删改查时将ht[0]的键值对rehash到ht[1]
- 所有的键值对均rehash完成,将rehashidx置-1。
这种方式主要是为了避免集中的rehash所带来的庞大计算量。因为渐进式rehash会同时使用ht[0]和ht[1],所以在rehash期间redis对这个字典的更新查找等操作会同时在这两个ht中进行。
跳跃表
跳跃表是一种有序数据结构,它通过在每个节点中维持多个指针指向其他节点从而实现跳跃访问其他节点,zset的底层便是跳跃表。在redis源码中server.h定义了跳跃表的结构:
1 | /* ZSETs use a specialized version of Skiplists */ |
我们看到zset 是由 dict(集合)和zskiplist(跳表)组成,zskiplist又包含了如下属性:
- header表头节点
- tail表尾节点
- length跳跃表中节点数量
- level 层数最大的节点的层数
其中 header 和 tail 是结构体zskiplistNode的指针,这个结构体便是跳表的节点,它有如下属性:
- ele:成员对象;
- score:分值,用来排序;
- backward:后退指针,用于从表尾向表头遍历
- level:数组,节点的层,包含forward(前进指针,用于表头向表尾遍历),span(跨度,用于记录两个节点之间的距离)
跳表的层可以包含多个元素,每个元素都包含指向一个节点的指针用于快速访问其他节点,比如程序访问节点1,节点的层包含了节点4的层,那么就可以跳跃到节点四,而不是一直遍历到节点4。
对象
redis 使用对象来表示数据库中的键值,当我们在redis数据库中创建一个键值对时,至少会生成两个对象,用于表示key和value。redis对象源码:
1 | typedef struct redisObject { |
属性说明:
- type:对象的类型,包括string,list,hash,set,zset
- encoding:编码,表示该对象使用了什么结构作为底层实现,包括 skiplist,linklist,ht等
- refcount:引用计数。它允许robj对象在某些情况下被共享
- lru: 做LRU替换算法用
- ptr: 数据指针。指向真正的数据。
redis 命令的多态,内存回收,内存共享,内存淘汰策略等特性都涉及到 redisObject,下一章节将单独讲解相关特性,感谢阅读。
