
kafka 原理深度解读
前文介绍了kafka的一些基本原理,接下来我们深入了解下关于kafka的一些机制和优化
partition 文件存储机制
前文提到过,一个topic是分成多个partition 存储的;topic是逻辑上的概念,partition是物理上的概念,如图所示: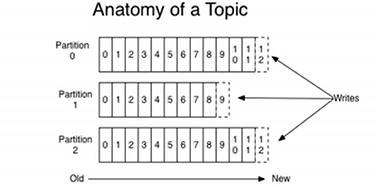
通过图片我们可以看出,虽然每个partition内部是有序的,但对于整个topic而言它是无法保证有序性的。
partition 的数据会以 日志文件的形式存储到磁盘中,在配置文件 server.properties 中通过属性 log.dirs 指定。
在该文件夹下会根据topic和序号来创建文件夹,在该 partition 文件夹中以 .log 结尾的文件是实际存储数据的文件,当生产者生产数据,。
以 .index 结尾的文件是索引文件,index 和log 组成一个 segment。 .log 文件默认只会保持7天内的数据,通过 log.retention.hours 配置项指定数据保持时长。
当.log 文件超出最大值时会创建新的 .log文件和.index文件,也就是一个新的segment;其中文件的名称以消息起始偏移量命名。log.segment.bytes 指定log文件的最大值。当我们去寻找一条消息的时候,会先根据偏移量来定位到属于哪一个 segment,
再通过二分查找从index文件中寻找该偏移量对应的索引,再通过索引去log文件中找到真正的消息。
数据可靠性保证
为保证producer 发送的数据不丢失,broker 接收到数据后都需要对producer发送ack(确认接收) ,如果producer 未收到ack则会重新发送该条消息。producer 的 ack 策略又分为三种:
- ack=0 producer不等待broker同步完成的确认,继续发送下一条(批)信息
- ack=1 producer要等待leader成功收到数据并得到确认,才发送下一条message。
- ack=-1 producer得到follwer确认(全副本同步完成),才发送下一条数据
isr(同步副本表)
采用全副本同步完成再ack会有一个问题:
当leader 接收完数据,所有的follower开始同步数据,但一旦有一个follower不能与leader进行同步,那leader会一直等下去,这样会非常的浪费时间。
为此kafka引入了 isr 机制——leader会维护一个动态的 isr(in-sync replica set)列表,这个列表维护了和leader保持同步的集合。当ISR中的follower完成数据的同步之后,leader就会发送ack。如果follower 长时间未向leader同步数据,则该follower将会被踢出 isr,当其他满足条件的follower也会被加入到isr。这个同步最大时间配置项为replica.lag.time.max.ms 参数设置。如果leader故障了,也会从isr的follower中选举新的leader。
数据一致性问题
因为副本的消息数是存在差异的,可能leader10条,而follower只同步了8条;当leader挂掉,数据就有可能会发生丢失,通过一种机制来保证消费者消费数据的一致性就很有必要了。kafka的数据一致性通过 LEO(每个副本的最后一条o’f’fset)和HW(所有的LEO中最小的那个)来保证。示意图: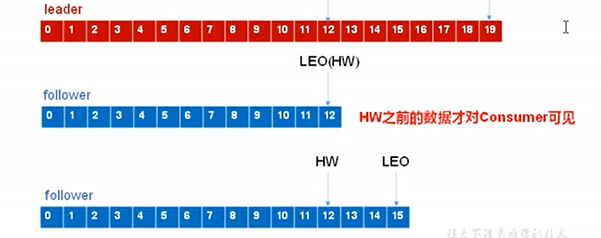
消费者只能看到offset<=HW 的消息。
消费策略
kafka 对消息消费的处理有两种:
- (at least once)至少一次
- (at most once)至多一次
- (exactly once) 有且只有一次
因为ack机制的存在,producer 向kafka发送消息时如果 ack=0,由于producer不等确认消息是否投递成功就不管了 ,可能丢失数据,此时消费者最多消费一次消息;如果ack=1,当producer未收到消息确认投递成功时会再次投递,这个时候可能消息被投递了多次,可能会存在重复消费的情况。当kafka开启数据幂等性且ack=1的时候,此时重复的消息会被去重,因此不会产生重复消费的情况。
启用幂等性的方式是将producer中的参数 enable.idompotence 设置为true。
消费者相关特性
和rabbitMQ一样,可以指定消费者消费消息是推模式还是拉模式,逻辑是和 rabbit 一样的,这里就不多做解释了。在消费者组中,有多个消费者,一个topic中有多个partition。那么消息的分配是怎么样的呢,首先前文提到过一个消费者组中的消费者不能同时消费同一个partition,这是基本原则。
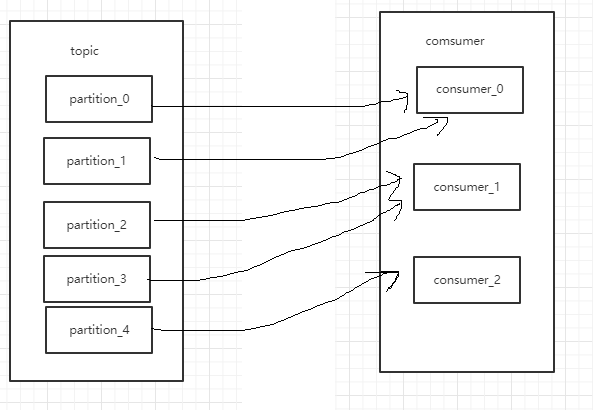
然后partiotion的分配机制有两种,一种是range(范围) 一种是 RoundRobin(轮询),range示 意图:
RoundRobin 示意图:
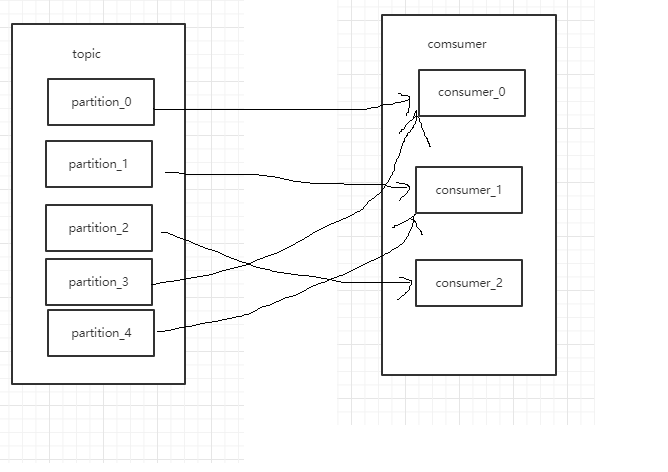
由于consumer也可能会宕机挂掉,当consumer恢复的时候必须要能够从上一次消费的地方重新开始消费。所以consumer需要实时记录自己消费到了哪一个offset,以便能够恢复到宕机前状态。
kafka高效读写保证
kafka的producer生产数据,要以追加的形式写入到log文件中,这个写磁盘的过程是顺序写,相对于磁盘的随机写来说,这个效率要高出很多,这个是kafka高效读写的保证之一。而另外的一个保证高效读写的技术是零拷贝,用过netty的小伙伴应该知道这个技术,中间少了两次用户态的切换。
kafka 集群特性
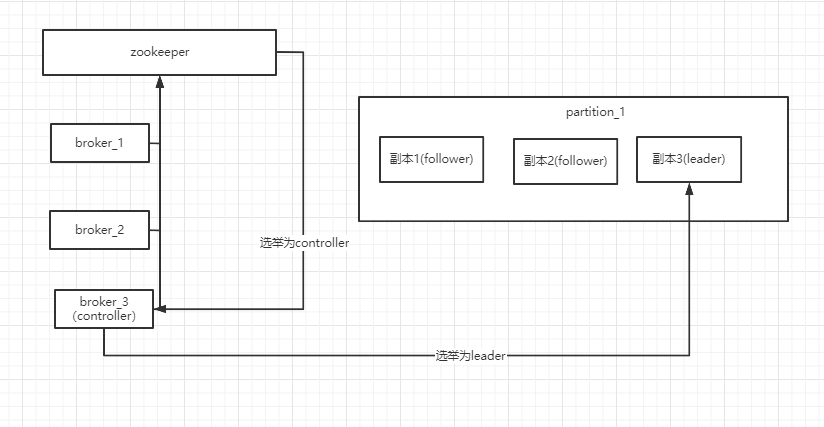
kafka的集群中会有一个broker会被选举为 controller,负责管理集群broker的上下线,所有topic的副本leader的选举工作,
而controller的这些管理工作都是需要依赖于kafka的。下图为leader的选举示意图:
kafka特性介绍完毕,接下来介绍kafka 事务相关的知识
