
kafka 原理
消息队列一般包含两种模式,一种是点对点的模式,一种是发布订阅的模式。前文提到过 kafka 是一款基于发布订阅的消息队列。
那么kafka是怎么去发布消息,怎么去保存消息,订阅消息的呢?首先我们从kafka的发布订阅模型开始分析。
下图为kafka的发布订阅模型: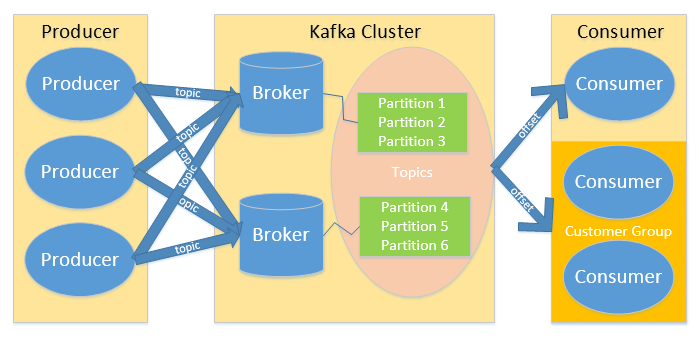
kafka 运行流程
kafka 总体流程可以粗略的归纳为:
Producer 生产一个消息并指定消息的主题 Topic -> producer 将生产的消息投递给 kafka cluster -> kafka cluster
将消息根据 Topic 拆分成多个partition 存储到各个 broker 中 -> 消费者组订阅主题,负载均衡的消费消息。
接下来我们分析 kafka 的数据分区保存和记录消息消费与生产的方式。
partition(分区)
kafka 对于 topic 有一个分区的默认值,通过config/server.properties中通过配置项num.partitions来指定新建Topic的默认Partition数量,
同时也可在创建Topic时通过参数指定或者在Topic创建之后通过Kafka提供的工具修改。生产者将数据写入到kafka主题后,
kafka通过不同的策略将数据分配到不同分区中,常见的有三种策略,轮询策略,随机策略,和按键保存策略。
在消费者这一端,一个consumer可以消费一个或多个partition,1个partition只能被同组的一个consumer消费,
但是可以被不同组的多个 consumer 消费。如果一个consumer group中的consumer个数多于topic中的partition的个数,
多出来的consumer会闲置。
分区本身会有多个副本,这多个副本中只有一个是leader,而其他的都是follower。仅有leader副本可以对外提供服务。
通常follower不和leader在同一个broker中,这样当leader 挂掉 follower 不会跟着挂,
而是从众多follower中选一个出来作为leader继续提供服务。
offset
每个分区中还会维护一个 offset (偏移量),这是一个很重要的数据,消息的存取都依赖它。
现在我们可以先简单的理解为往每个分区中写一条数据就会加一个偏移量,而消费一条数据就会减一个偏移量,就好像队列的游标一样。
后文会具体分析它的工作原理。下图为 offset 示意图:
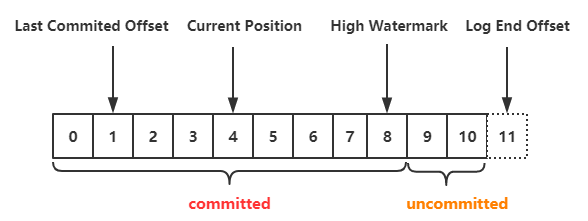
通常由如下几种 Kafka Offset 的管理方式:
Spark Checkpoint:在 Spark Streaming 执行Checkpoint 操作时,将 Kafka Offset 一并保存到 HDFS 中。
HBASE、Redis 等外部 NOSQL 数据库:这一方式可以支持大吞吐量的 Offset 更新。
ZOOKEEPER:老版本的位移offset是提交到zookeeper中的,目录结构是 :/consumers/<group.id>/offsets/
/ ,当存在频繁的 Offset 更新时,ZOOKEEPER 集群本身可能成为瓶颈。 KAFKA:存入自身的一个特殊 Topic中,这种方式支持大吞吐量的Offset 更新,又不需要手动编写 Offset 管理程序或者维护一套额外的集群。
后文我们会介绍关于 kafka 的 partition 与 offset 的一些机制,如数据存储与同步,分区原则,分区策略,可靠性保证,高效读写原理等。
