软件开发的生命周期
传统的软件开发生命周期是指软件产品从构思开始,经过定义、开发、使用和维护直到最后废弃的全过程。按照传统的软件生命周期方法,可以把软件生命周期划分为软件定义、软件开发、软件运行与维护三个阶段。
more >>我们在web 项目中讨论的状态机通常是指状态机这种设计模式。该设计模式属于行为型设计模式,
它允许对象在内部状态改变时改变其行为,看起来好像修改了自身的类。这种模式通过将状态相关的行为封装到不同的状态对象中,解决了复杂条件判断(如大量if-else或switch-case)导致的代码臃肿问题。
more >>链式调用位于LangChain三层核心架构中的中间层——工作流API抽象层。链就是负责将这些组件按照某一种逻辑,顺序组合成一个流水线的方式。比如我们要构建一个简单的问答链,就需要把大模型组件和标准输出组件用链串联起来。
more >>王阳明于明武宗正德元年(1506年),因反对宦官刘瑾,被廷杖四十,谪贬至贵州龙场(贵阳西北七十里,修文县治)当驿丞。龙场万山丛薄,苗、僚杂居。在龙场这既安静又困难的环境里,王阳明结合历年来的遭遇,日夜反省。一天半夜里,他忽然有了顿悟,认为心是感应万事万物的根本,由此提出心即理的命题。认识到“圣人之道,吾性自足,向之求理于事物者误也。”这就是著名的“龙场悟道”,我们这一篇博客讨论的就是阳明心学。小伙伴看到阳明心学可能就联想到唯心主义,阳明心学确实是唯心主义,但不全是。我们现在想过的很多问题,古人早替我们想过了,而且想的更深邃。阳明心学能传承这么多年,自然有它的可取之处,这里我们取的就是阳明心学中的知行合一。
more >>KubeSphere是k8s控制台,ubeSphere 目前提供了工作负载管理、微服务治理、DevOps 工程、Source to Image、多租户管理、多维度监控、日志查询与收集、告警通知、服务与网络、应用管理、基础设施管理、镜像管理、应用配置密钥管理等功能模块。
more >>redis 的客户端有jedis、lettuce、redission;我个人比较推荐的是redission,因为它的分布式锁和缓存实在是太优秀了。 Redisson采用了基于NIO的Netty框架,封装了大家常用的集合类以及原子类、锁等工具。
本章节主要介绍redission 中重要的两个点:数据结构和锁
redis持久化方式有两种,一种是RDB,一种是aof。
RDB持久化是指在指定的时间间隔内将内存中的数据集快照写入磁盘。
AOF持久化以日志的形式记录服务器所处理的每一个写操作,查询操作不会记录,以文本的方式记录,可以打开文件看到详细的操作记录。
在redis源码中数据库的结构由server.h/redisDb表示,
redisDb结构的dict字典保存了数据库中的所有键值对,我们将这个字典称为键空间(key space),redisDb源码:
前文我们看过redisObject的源码:
1 | typedef struct redisObject { |
下面我们来了解redisObject相关机制
redis中没有直接使用C语言的字符串,而是自定义了一种名为简单动态字符串的抽象类型——SDS。我们下载redis源码,可以在src目录下找到一个sds.h的文件,打开这个文件查看它的部分代码:
vagrant 相对于 vmware 而言更轻量级,操作更简便移植性更强,如果我们需要学习k8s或者搭建一些集群的话建议使用 Virtualbox+Vagrant。
Vagrant 是创建虚拟机的工具,Virtualbox 是vagrant 管理工具,而且这两个软件是开源的,不需要我去付费或者破解。
vagrant 下载地址:https://www.vagrantup.com
virtualbox 下载地址:https://www.virtualbox.org/wiki/Downloads
下载安装完成后,我们还需要下载vagrant镜像
镜像下载地址:https://app.vagrantup.com/boxes/search
Cluster : 集群是指由Kubernetes使用一系列的物理机、虚拟机和其他基础资源来运行你的应用程序。
Node : 运行着Kubernetes的物理机或虚拟机,并且pod可以在其上面被调度。
Pod : k8s的最小调度单元,一个pod 可以包含多个容器,k8s无法直接操作容器,只能操作pod
Label : 一个label是一个被附加到资源上的键/值对,譬如附加到一个Pod上,为它传递一个用户自定的并且可识别的属性.Label还可以被应用来组织和选择子网中的资源
selector:是一个通过匹配labels来定义资源之间关系得表达式,例如为一个负载均衡的service指定所目标Pod.
Deployment: 控制pod生命周期的pod控制器
Service : 一个service定义了访问pod的方式,比如固定的IP地址和与其相对应的DNS名之间的关系。
Volume: 目录或者文件夹
Namespace : 命名空间,起到资源分组he隔离的作用
more >>在实际项目中往往需要在流水线执行过程中发送通知邮件到相应的开发运维人员的邮箱中,jenkins 可以通过插件 Email Extension Plugin 进行相关配置。
进入jenkins系统设置中找到email 相关配置:
配置内容包括邮箱服务器(参考 spring 发送邮件功能),邮箱后缀等,jenkins 旁边的问号图标都有相关配置项说明,需要注意的是jenkins 内置了一些变量,可查看 Content Token Reference 项。完成基本的邮件配置完成后,还需要再流水线中配置发送邮件相关信息
docker是Docker.inc 公司开源的一个基于LXC技术之上构建Container容器引擎技术,Docker基于容器技术的轻量级虚拟化解决方案,实现一次交付到处运行。
docker实现程序集装箱的概念,把我们需要交付的内容集装聚合成一个文件(镜像文件)直接交付。
docker 架构图: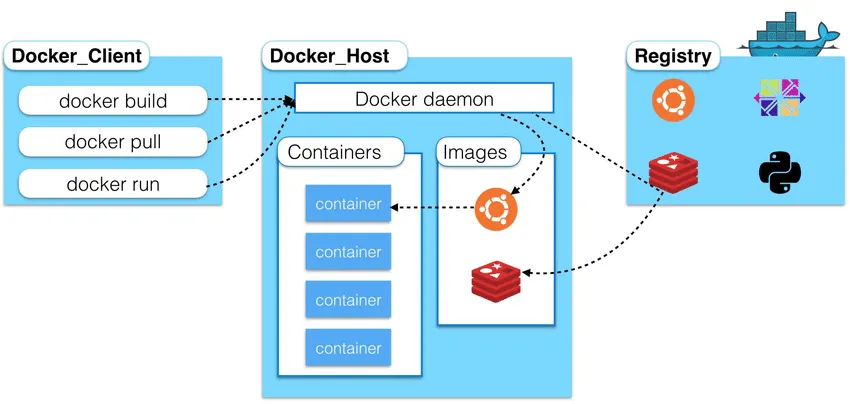
从架构图中我们可以看出,docker有三大核心,包括容器,仓库,镜像
more >>ansible是一个基于python的自动化运维工具,实现了批量系统配置、批量程序部署、批量运行命令等功能。ansible包括部署和使用简单、默认使用ssh协议、轻量级等特点。
more >>pipeline是部署流水线,它支持脚本和声明式语法,能够比较高自由度的构建jenkins任务.个人推荐使用这种方式去构建jenkins。
Jenkins 1.x只能通过界面手动配置来配置描述过程,想要配置一些复杂度高的任务,只能选择自由风格的项目,通过选项等操作进行配置,让jenkins可以下载代码、编译构建、然后部署到远程服务器上,这样显然是不方便管理和移植的。
pipeline的功能由pipeline插件提供,我们可以创建一个jenkinsfile来申明一个任务。接下来我们创建一个最简单的pipeline。登录jenkins,点击创建item:
more >>Jenkins是一款开源 CI&CD 软件,用于自动化各种任务,包括构建、测试和部署软件,CI&CD:
之前我做过一款 chrome代理插件——poseidon-chrome-proxy,这个插件的功能是通过一些配置将浏览器中的请求代理到你配置的服务器上去。这款插件的局限性是只能使用在谷歌浏览器中,而且无法代理https请求,这是因为谷歌浏览器限制了pac脚本对https请求的代理;不仅如此,该插件还存在dns污染的问题,虽然可以通过清除浏览器缓存来解决,但是也是比较糟心。最近项目中恰好遇到了需要对https进行代理的需求,经过我的研究,最终找到了一个比较满意的解决方案,它就是fiddler。
fiddler 是一款专门用于抓取http请求的抓包工具,当启动该工具时,pc端的请求会先被代理到该工具再转发到服务器,因此我们就可以在请求转发前对请求的协议,请求头,路径,请求内容等信息进行修改。而且通过该工具你还能记录某个请求的数据并进行回放或打断点,相比较代理插件,不仅适用范围更广,调试bug也更方便。
more >>我们之前配置的流控规则都是存储在应用的内存中的,这种方式明显无法满足我们实际开发的需求,一旦项目被重启,流控规则就被初始化了,需要我们再次去重新配置,因此规则的持久化就显得很有必要了。
本节会介绍几类主流持久化方式并对自定义持久化做介绍
more >>sentinel 是阿里开源的流量控制,熔断降级,系统负载保护的一个Java组件;
Sentinel 分为两个部分:
核心库(Java 客户端)不依赖任何框架/库,能够运行于所有 Java 运行时环境,同时对 Dubbo / Spring Cloud 等框架也有较好的支持。
控制台(Dashboard)基于 Spring Boot 开发,打包后可以直接运行,不需要额外的 Tomcat 等应用容器。
前文介绍了 kafka 的相关特性和原理,这一节我们将学习怎么在springboot中使用kafka;
首先导入依赖
1 | <dependency> |
消息队列一般包含两种模式,一种是点对点的模式,一种是发布订阅的模式。前文提到过 kafka 是一款基于发布订阅的消息队列。
那么kafka是怎么去发布消息,怎么去保存消息,订阅消息的呢?首先我们从kafka的发布订阅模型开始分析。
kafka 是一款基于发布订阅的消息系统,Kafka的最大的特点就是高吞吐量以及可水平扩展,
Kafka擅长处理数据量庞大的业务,例如使用Kafka做日志分析、数据计算等。
ListenerContainer 的使用在消费端,我们的消费监听器是运行在 监听器容器之中的( ListenerContainer ),springboot 给我们提供了两个监听器容器 SimpleMessageListenerContainer 和 DirectMessageListenerContainer 在配置文件中凡是以 spring.rabbitmq.listener.simple 开头的就是对第一个容器的配置,以 spring.rabbitmq.listener.direct 开头的是对第二个容器的配置。其实这两个容器类让我很费劲;首先官方文档并没有说哪个是默认的容器,似乎两个都能用;其次,它说这个容器默认是单例模式的,但它又提供了工厂方法,而且我们看 @RabbitListener 注解源码:
这一章节我们会学习rabbitMQ在项目生产中一些重要的特性,如持久化,消息确认机制,消息过期等特性。只要能利用好这些特性,我们就能开发出可用性强的,功能强大的MQ系统。
more >>从这一节开始我们进入rabbitMQ的实战环节,项目环境是spring-boot 加maven。首先让我们创建一个spring-boot项目,然后引入web依赖和 rabbitMQ的依赖
more >>前文我们学习了 MQ的相关知识,现在我们来学习一下实现了AMQP协议的 rabbitMQ 中间件。rabbitMQ 是使用 erlang 语言编写的中间件(erlang之父 19年4月去世的,很伟大一个程序员)。
对 rabbitMQ 我们已经有了初步的了解,现在我们来安装 rabbitMQ 来进行一些操作。因为大部分人的操作系统都是windows 而且作者本人使用的也windows系统。所以这里只介绍在windows上安装rabbitMQ。mac用户自行解决(仇富脸)。
more >>java -Xmx3550m -Xms3550m -Xmn2g -Xss128k
-Xmx3550m:设置JVM最大可用内存为3550M。
-Xms3550m:设置JVM促使内存为3550m。此值可以设置与-Xmx相同,以避免每次垃圾回收完成后JVM重新分配内存。
-Xmn2g:设置年轻代大小为2G。整个JVM内存大小=年轻代大小 + 年老代大小 + 持久代大小。持久代一般固定大小为64m,所以增大年轻代后,将会减小年老代大小。此值对系统性能影响较大,Sun官方推荐配置为整个堆的3/8。
-Xss128k:设置每个线程的堆栈大小。JDK5.0以后每个线程堆栈大小为1M,以前每个线程堆栈大小为256K。更具应用的线程所需内存大小进行调整。在相同物理内存下,减小这个值能生成更多的线程。但是操作系统对一个进程内的线程数还是有限制的,不能无限生成,经验值在3000~5000左右。
java -Xmx3550m -Xms3550m -Xss128k -XX:NewRatio=4 -XX:SurvivorRatio=4 -XX:MaxPermSize=16m -XX:MaxTenuringThreshold=0
-XX:NewRatio=4:设置年轻代(包括Eden和两个Survivor区)与年老代的比值(除去持久代)。设置为4,则年轻代与年老代所占比值为1:4,年轻代占整个堆栈的1/5
-XX:SurvivorRatio=4:设置年轻代中Eden区与Survivor区的大小比值。设置为4,则两个Survivor区与一个Eden区的比值为2:4,一个Survivor区占整个年轻代的1/6
-XX:MaxPermSize=16m:设置持久代大小为16m。
-XX:MaxTenuringThreshold=0:设置垃圾最大年龄。如果设置为0的话,则年轻代对象不经过Survivor区,直接进入年老代。对于年老代比较多的应用,可以提高效率。如果将此值设置为一个较大值,则年轻代对象会在Survivor区进行多次复制,这样可以增加对象再年轻代的存活时间,增加在年轻代即被回收的概论。
JVM提供了大量命令行参数,打印信息,供调试使用。主要有以下一些:
-XX:+PrintGC
输出形式:[GC 118250K->113543K(130112K), 0.0094143 secs]
[Full GC 121376K->10414K(130112K), 0.0650971 secs]
-XX:+PrintGCDetails
-XX:+PrintGCTimeStamps -XX:+PrintGC:PrintGCTimeStamps可与上面两个混合使用
-XX:+PrintGCApplicationConcurrentTime:打印每次垃圾回收前,程序未中断的执行时间。可与上面混合使用
-XX:+PrintGCApplicationStoppedTime:打印垃圾回收期间程序暂停的时间。可与上面混合使用
-XX:PrintHeapAtGC:打印GC前后的详细堆栈信息
more >>责任链(Chain of Responsibility)模式的定义:为了避免请求发送者与多个请求处理者耦合在一起,将所有请求的处理者通过前一对象记住其下一个对象的引用而连成一条链;当有请求发生时,可将请求沿着这条链传递,直到有对象处理它为止。
责任链模式也叫职责链模式。
在责任链模式中,客户只需要将请求发送到责任链上即可,无须关心请求的处理细节和请求的传递过程,所以责任链将请求的发送者和请求的处理者解耦了。
more >>策略(Strategy)模式的定义:该模式定义了一系列算法,并将每个算法封装起来,使它们可以相互替换,且算法的变化不会影响使用算法的客户。策略模式属于对象行为模式,它通过对算法进行封装,把使用算法的责任和算法的实现分割开来,并委派给不同的对象对这些算法进行管理。策略模式有以下优点:
代理模式的定义:由于某些原因需要给某对象提供一个代理以控制对该对象的访问。这时,访问对象不适合或者不能直接引用目标对象,代理对象作为访问对象和目标对象之间的中介。
代理模式的主要优点有:
代理模式在客户端与目标对象之间起到一个中介作用和保护目标对象的作用;
代理对象可以扩展目标对象的功能;
代理模式能将客户端与目标对象分离,在一定程度上降低了系统的耦合度;
其主要缺点是:
在客户端和目标对象之间增加一个代理对象,会造成请求处理速度变慢;
增加了系统的复杂度;
组合(Composite)模式的定义:有时又叫作部分-整体模式,它是一种将对象组合成树状的层次结构的模式,用来表示“部分-整体”的关系。组合模式使得客户端代码可以一致地处理单个对象和组合对象,无须关心自己处理的是单个对象,还是组合对象,这简化了客户端代码;
more >>装饰器(Decorator)模式指在不改变现有对象结构的情况下,动态地给该对象增加一些职责(即增加其额外功能)的模式,它属于对象结构型模式。采用装饰模式扩展对象的功能比采用继承方式更加灵活;可以设计出多个不同的具体装饰类,创造出多个不同行为的组合。但是装饰模式增加了许多子类,如果过度使用会使程序变得很复杂。
more >>建造者模式(Builder)是一步一步创建一个复杂的对象,它允许用户只通过指定复杂对象的类型和内容就可以构建它们,用户不需要知道内部的具体构建细节。建造者模式属于对象创建型模式。我们获得一个对象的时候不是直接new这个对象出来,而是对其建造者进行属性设置,然后建造者在根据设置建造出各个对象出来。建造者模式又可以称为生成器模式。
more >>单例模式 (Singleton Pattern)使用的比较多,比如我们的 controller 和 service 都是单例的,但是其和标准的单例模式是有区别的。这种类型的设计模式属于创建型模式,它提供了一种创建对象的最佳方式。这种模式涉及到一个单一的类,该类负责创建自己的对象,同时确保只有单个对象被创建。这个类提供了一种访问其唯一的对象的方式,可以直接访问,不需要实例化该类的对象。
more >>桥接模式(Bridge Pattern):将抽象部分与它的实现部分分离,使它们都可以独立地变化。它是一种对象结构型模式,又称为柄体(Handle and Body)模式或接口(Interface)模式。
设想如果要绘制矩形、圆形、椭圆、正方形,我们至少需要4个形状类,但是如果绘制的图形需要具有不同的颜色,如红色、绿色、蓝色等,此时至少有如下两种设计方案:
对于有两个变化维度(即两个变化的原因)的系统,采用第二种方案来进行设计系统中类的个数更少,且系统扩展更为方便。第二种方案即是桥接模式的应用。桥接模式将继承关系转换为关联关系,从而降低了类与类之间的耦合,减少了代码编写量。对于有两个变化维度(即两个变化的原因)的系统,采用桥接模式开发更为方便简洁。桥接模式将继承关系转换为关联关系,从而降低了类与类之间的耦合,减少了代码编写量。
more >>简单工厂模式(Simple Factory Pattern):又称为静态工厂方法(Static Factory Method)模式,它属于类创建型模式。在简单工厂模式中,可以根据参数的不同返回不同类的实例。简单工厂模式专门定义一个类来负责创建其他类的实例,被创建的实例通常都具有共同的父类。
简单工厂模式包含如下角色:
从官网 https://apache.org/dist/zookeeper/zookeeper-3.5.5/ 上下载zk(注意windows也是下载 tar.gz后解压),./conf下有个zoo_sample.cfg 复制到同目录下改名为zoo.cfg,在目录下新建data和log文件夹,修改zoo.cfg中的 dataDir 和 dataLogDir为 data和log的路径。现在启动zk,在bin目录下有个zkServer.cmd,运行启动。启动ZK客户端对ZK进行简单的读写操作,在bin目录下打开cmd,运行:
1 | ### 初始化git 仓库 |
Gradle是一个构建工具,定位和maven一样,用于管理项目依赖和构建项目。和maven比起来的优势是:语法更灵活,更方便管理项目(个人很讨厌XML)。
gradle具有以下特点:
前段时间写了一篇关于nacos的文章,本人还是很期待nacos成长起来的。nacos在其官方文档里面说nacos未来会支持grpc,正好我对grpc也抱有极大兴趣,于是基于springboot和gradle做了一个小demo对它们进行了整合,初步研究了一下,期待nacos成熟起来,组成一套Spring Cloud+gradle+nacos+grpc+sentinel的完全体。这篇博客的目的是知识储备,并不是讨论解决开发中某些问题。
弄了一天,得到一个结论,gradle+grpc+git subtree 不是目前的我能驾驭的,弃文;等对gradle足够熟练再回来弄。
more >>代理是一种软件设计模式,这种设计模式不直接访问被代理对象,而访问被代理对象的方法,详尽的解释可参考《java设计模式之禅》,里面的解释还是很通俗的。给个《java设计模式之禅》下载地址:https://pan.baidu.com/s/1GdFmZSx67HjKl_OhkwjqNg
在JDK中提供了实现动态代理模式的机制,cglib也是一个用于实现动态代理的框架,在这里我介绍jdk自带的动态代理机制是如何使用的。先上代码再慢慢解释:
more >>在JDK 1.2以前的版本中,若一个对象不被任何变量引用,那么程序就无法再使用这个对象。对象引用被划分成简单的两种状态:可用和不可用。从JDK 1.2版本以后,对象的引用被划分为4种级别,从而使程序能更加灵活地控制对象的生命周期,引用的强度由高到低为:强、软、弱、虚引用。
对象生命周期:在JVM运行空间中,对象的整个生命周期大致可以分为7个阶段:创建阶段(Creation)、应用阶段(Using)、不可视阶段(Invisible)、不可到达阶段(Unreachable)、可收集阶段(Collected)、终结阶段(Finalized)与释放阶段(Free)。上面的这7个阶段,构成了 JVM中对象的完整的生命周期。
more >>git subtree可将多个git项目合并在一起,可解决protobuf更新的问题;
打包maven私有仓库也可行,但是maven私有仓库不适合频繁更新,而protobuf更新会很频繁。
1 |
|
每次开机都启动一堆软件,很麻烦,该肿么办?
写个批处理文件 步骤(这里以启动微信为例 ):
start “xx” “xxx”
xx 代表程序名称,可以随便起;xxx代表你想启动的程序的位置 获取程序位置的方法:
more >>这篇博客会记录我的一些刷题心得
两数之和
给定一个整数数组 nums 和一个目标值 target,请你在该数组中找出和为目标值的那 两个 整数,并返回他们的数组下标。
你可以假设每种输入只会对应一个答案。但是,你不能重复利用这个数组中同样的元素。
more >>在nacos-0.3的时候我就开始关注,期间还写过一篇作为springcloud配置中心的使用记录的博客。在前不久,nacos终于出了正式版,赶个时髦出篇博客吹一波,[nacos官方文档](https://nacos.io/zh-cn/index.html)原文链接 http://www.ruanyifeng.com/blog/2018/07/cap.html
分布式系统的最大难点,就是各个节点的状态如何同步。CAP 定理是这方面的基本定理,也是理解分布式系统的起点。
Consistency 中文叫做”一致性”。意思是,写操作之后的读操作,必须返回该值。
Availability Availability 中文叫做”可用性”,意思是只要收到用户的请求,服务器就必须给出回应。
Partition tolerance 中文叫做”分区容错”。大多数分布式系统都分布在多个子网络。每个子网络就叫做一个区(partition)。分区容错的意思是,区间通信可能失败。
这三个指标不可能同时做到,一般来说,分区容错无法避免,因此可以认为 CAP 的 P 总是成立。CAP 定理告诉我们,剩下的 C 和 A 无法同时做到。对于Eureka而言,其是满足AP的。
作者:muggle
传统的IO又称BIO,即阻塞式IO,NIO就是非阻塞IO了,而NIO在jdk1.7后又进行了升级成为nio.2也就是aio;
Java IO的各种流是阻塞的。这意味着,当一个线程调用read()或 write()时,该线程被阻塞,直到有一些数据被读取,或数据完全写入。该线程在此期间不能再干任何事情了。 Java NIO的非阻塞模式,使一个线程从某通道发送请求读取数据,但是它仅能得到目前可用的数据,如果目前没有数据可用时,就什么都不会获取。而不是保持线程阻塞,所以直至数据变的可以读取之前,该线程可以继续做其他的事情。 非阻塞写也是如此。一个线程请求写入一些数据到某通道,但不需要等待它完全写入,这个线程同时可以去做别的事情。 线程通常将非阻塞IO的空闲时间用于在其它通道上执行IO操作,所以一个单独的线程现在可以管理多个输入和输出通道(channel)。
作者:muggle
服务治理是微服务架构中最为核心和基础的模块。它主要用来实现各个微服务实例的自动化注册与发现。随着服务的越来越多,越来越杂,服务之间的调用会越来越复杂,越来越难以管理。而当某个服务发生了变化,或者由于压力性能问题,多部署了几台服务,怎么让服务的消费者知晓变化,就显得很重要了。不然就会存在调用的服务其实已经下线了,但调用者不知道等异常情况。这个时候有个服务组件去统一治理就相当重要了。Eureka便是服务治理的组件。
more >>muggle
类从被加载到虚拟机内存中内存中开始,到卸载出内存为止,它的整个生命周期包括:加载(loading)、验证(verification)、准备(preparation)、解析(resolution)、初始化(initialization)、使用(using)卸载(unloading)七个阶段。其中验证、准备、解析三个阶段统称为连接(linking)。
more >>标记-清除算法是最基础的算法,算法分为标记和清除两个阶段,首先标记出要清除的对象,在标记完后统一回收所有被标记的对象,标记方式为j《jvm系列之垃圾收集器》里面所提到的。这种算法标记和清除两个过程效率都不高;并且在标记清除后,内存空间变得很零散,产生大量内存碎片。当需要分配一个比较大的对象时有可能会导致找不到足够大的内存。 more >>
java内存在运行时被分为多个区域,其中程序计数器、虚拟机栈、本地方法栈三个区域随线程生成和销毁;每一个栈帧中分配多少内存基本上是在类结构确定下来时就已知的,在这几个区域内就不需要过多考虑回收问题,因为方法结束或者线程结束时,内存自然就跟着回收了。而堆区就不一样了,我们只有在程序运行的时候才能知道哪些对象会被创建,这部分内存是动态分配的,垃圾收集器主要关注的也就是这部分内存。
more >>作者:muggle
在语言层面上,创建一个对象通常是通过new关键字来创建,在虚拟机中遇到一条new指令时,首先将去检查这个指令的参数是否能在常量池中定位到一个类的符号引用,并且检查这个符号引用代表的类是否已被加载、解析和初始化过;如果没有的话就会先加载这个类;类加载检查完后,虚拟机将会为新生对象分配内存。对象所需内存的大小在类加载完成后便可完全确定,在堆中为对象划分一块内存出来。
虚拟机给对象分配内存的方式有两种——“指针碰撞”的方式和“空闲列表”的方式。如果java堆内存是绝对规整的,所有用过的内存放在一边,未使用的内存放在另一边,中间放一个指针作为指示器,那分配内存就只是把指针向未使用区域挪一段与对象大小相等的距离;这种分配方式叫指针碰撞式,如图1所示。
more >>作者:muggle
想要了解jvm,那对其内存分配管理的学习是必不可少的;java虚拟机在执行java程序的时候会把它所管理的内存划分成若干数据区域。这些区域有着不同的功能、用途、创建/销毁时间。java虚拟机所分配管理的内存区域如图1所示
程序计数器是一块比较小的内存空间,它可以看做是当前线程所执行的字节码的执行位置的指针。在虚拟机中字节码,解释器工作时就是通过改变这个计数器的值来选取下一条需要执行的指令;虚拟机完成分支、循环、跳转、异常处理、线程恢复等功能都需要依靠它。
我们知道jvm多线程是通过线程的轮流切换并分配处理器执行时间的的方式来实现的,在任何时刻,一个处理器都只会执行一条线程中的指令。为了使线程被切换后能恢复到正确的执行位置,每条线程的程序计数器都应该是独立的,各条线程之间的计数器互不干涉,独立存储————程序计数器的内存区域为线程私有的内存。
如果线程正在执行的是java方法,这个计数器记录的是正在执行的虚拟机字节码指令的地址;如果执行的是Native方法,这个计数器的值则为空。此内存区域是唯一一个在jvm规范中没有规定任何OutOfMemoryerror情况的区域
作者:muggle
cas(比较替换):无锁策略的一种实现方式,过程为获取到变量旧值(每个线程都有一份变量值的副本),和变量目前的新值做比较,如果一样证明变量没被其他线程修改过,这个线程就可以更新这个变量,否则不能更新;通俗的说就是通过不加锁的方式来修改共享资源并同时保证安全性。
使用cas的话对于属性变量不能再用传统的int ,long等;要使用原子类代替原先的数据类型操作,比如AtomicBoolean,AtomicInteger,AtomicInteger等。
以下分类是从多个同角度来划分,而不是以某一标准来划分,请注意
作者:muggle
同步和异步通常来形容一次方法的调用。同步方法一旦开始,调用者必须等到方法结束才能执行后续动作;异步方法则是在调用该方法后不必等到该方法执行完就能执行后面的代码,该方法会在另一个线程异步执行,异步方法总是伴随着回调,通过回调来获得异步方法的执行结果;
很多人都将并发与并行混淆在一起,它们虽然都可以表示两个或者多个任务一起执行,但执行过程上是有区别的。并发是多个任务交替执行,多任务之间还是串行的;而并行是多个任务同时执行,和并发有本质区别。
对计算机而言,如果系统内只有一个cpu,而使用多进程或者多线程执行任务,那么这种情况下多线程或者多进程就是并行执行,并行只可能出现在多核系统中。当然,对java程序而言,我们不必去关心程序是并行还是并发。
作者:muggle
markdown语法学习成本低,而且非常方便排版,如果你经常写文章,那么你就很有必要掌握markdown了,而且在vscode中编写markdown也非常方便,只需掌握几个快捷键,安装几个插件就能极大的提高你的写作效率。
more >>作者:muggle
springsecurity是一个典型的责任链模式;我们先新建一个springboot项目,进行最基本的springsecurity配置,然后debug;我这里使用的开发工具是idea.建议大家也使用idea来进行日常开发。好了话不多说,开始:
more >>作者:muggle
netty框架代码很猛(读源码有益身心健康),学习起来也比较难;在阅读这篇文章我假设你有了一定nio基础,tcp网络协议基础,否则不建议阅读。
关于netty的学习视频我推荐B站张龙的教学视频,讲的很不错。学netty之前先学会用,然后在去看他的原理这样学起来会轻松不少。
more >>Logback是由log4j创始人设计的另一个开源日志组件,分为三个模块:
logback-core:其它两个模块的基础模块
logback-classic:它是log4j的一个改良版本,同时它完整实现了slf4j API使你可以很方便地更换成其它日志系统如log4j或JDK14 Logging
logback-access:访问模块与Servlet容器集成提供通过Http来访问日志的功能
在springboot中我们通过xml配置来操作logback
1 | /* |
在数学里,幂等有两种主要的定义:在某二元运算下,幂等元素是指被自己重复运算(或对于函数是为复合)的结果等于它自己的元素。如,乘法运算下,0和1符合的自乘运算符和幂等,即s*s=s某一元运算为幂等的时,其作用在任一元素两次后会和其作用一次的结果相同。例如,高斯符号便是幂等的,即f(f(x))=f(x)在计算机中,表示对同一个过程应用相同的参数多次和应用一次产生的效果是一样,这样的过程即被称为满足幂等性在分布式和前后端分离的的项目中,对于restful风格的接口,我们需要保证其接口的幂等性,说白了就是就是一个接口被反复调用不会影响最终结果;为什么呢,因为前后端分离的项目可能会发生这样的场景:前端发出一个请求,但这个请求被阻塞了,然后其重试机制再次发起请求,而恰好此时被阻塞的那个请求又好了,那么这个时候,会对后端发起连续两次请求;对于 get,put,delete 都没问题,连续的两次或者三次都不会影响请求处理结果,但post就有问题了;它会往数据库插入两条数据。
more >>
缺失模块。
1、请确保node版本大于6.2
2、在博客根目录(注意不是yilia根目录)执行以下命令:
npm i hexo-generator-json-content --save
3、在根目录_config.yml里添加配置:
jsonContent:
meta: false
pages: false
posts:
title: true
date: true
path: true
text: false
raw: false
content: false
slug: false
updated: false
comments: false
link: false
permalink: false
excerpt: false
categories: false
tags: true